Learning VIT's
One of my goals for this year is to find new applications of NLP techniques in new areas such as robotics. In the past I had a few experiences in robotics whether it was building simple Robots using arduinos or RPI’s with simple image recognition or designing odometry systems using ROS ( in which I sucked terribly at in my first year of uni and I’m honestly ashamed of that repo. ). So in the following months I’ll try to delve a bit deeper in the world of VLA’s, which is a topic that I’m actively considering doing my master thesis on.
The first step of this journey starts with understanding how ViT’s work and by making a simple ViT implementation using pytorch.
Logic wise ViT’s seem extremely simple, basically we take an input image we divide it into chunks with a fixed size (ie 32x32) in a grid like structure then we feed these patches after a linearization process as if they’re tokens into a Transformer whose output’s part is then fed to an MLP layer having our classes. The various tokens we obtain with the chunking process are encoded positionally to indicate their position on the grid, in a similar way in which is done in a “traditional text based transformer”.
Ok so summing up we have 5 steps.
- Patching the image (aka cutting it into chunks) and Linearization or Flattening of the chunks
- Positional Encoding
- Multi Head Attention
- Transformer Encoder Block
- Putting it all together in a Vision Transformer with an MLP for multi-label classification
Image Patching
Our goal in this section is to take our input image and split it into equal sized blocks which are then going to be flattened to be used as input tokens by our transformer. It’s basically a simple tokenizer for images.
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=1, embed_dim=768):
super().__init__()
self.patch_size = patch_size
self.unfold = nn.Unfold(kernel_size=patch_size, stride=patch_size)
self.patch_embed = nn.Linear(in_channels * patch_size ** 2, embed_dim)
self.img_size = img_size
self.embed_dim = embed_dim
def forward(self, x):
"""
Takes a [Batch_Size, 1, 224, 224] tensor and splits it into 16x16 chunks which then get flattened into 196 patches each flattened to 256 dim.
which get projected on our embedding dim of 768 resulting in a tensor shaped: [B, 196, 768]
"""
patches = self.unfold(x)
patches = patches.transpose(1, 2)
return self.patch_embed(patches)
self.unfold(x) slides a patch_size x patch_size window over our image with no overlap. And the result of it is a tensor shaped [batch_size, 16*16, num_of_patches]. Then patches.transpose(1, 2) transposes the first element with the second one [batch_size, 256, 196] -> [batch_size, 196, 256], the patch_embed function projects these tensors on our embedding dimension, giving us a final tensor shape of [B, 196, 768].
Positional Encoding
For this part I went directly with an implementation of a 2D-RoPe implementation found on: s-chh/2D-Positional-Encoding-Vision-Transformer.
I chose to use the 2D-RoPE approach because of its ability to conserve better the positional relationship between patches which is crucial for the task of classifying chest x-rays.
This positional encoding mechanism is necessary because Transformers aren’t aware of the positions of the tokens in the input sequence. The RoPE mechanism allows us to include the relative position information between the input tokens in the tokens themselves, by rotating the Q and K vectors by an angle proportional to their position, so that the dot product between two vectors naturally contains their relative distance. a deep dive into RoPE
# X-axis specific values
def get_x_positions(n_patches, start_idx=0):
n_patches_ = int(n_patches ** 0.5) # Number of patches along 1 dimension
x_positions = torch.arange(start_idx, n_patches_ + start_idx) # N_
x_positions = x_positions.unsqueeze(0) # 1, N_
x_positions = torch.repeat_interleave(x_positions, n_patches_, 0) # N_ , N_ Matrix to replicate positions of patches on x-axis
x_positions = x_positions.reshape(-1) # N_ , N_ -> N_ ** 2 = N
return x_positions
# Y-axis specific values
def get_y_positions(n_patches, start_idx=0):
n_patches_ = int(n_patches ** 0.5) # Number of patches along 1 dimension
y_positions = torch.arange(start_idx, n_patches_+start_idx) # N_
y_positions = torch.repeat_interleave(y_positions, n_patches_, 0) # N_ , N_ -> N_ ** 2 = N Matrix to replicate positions of patches on y-axis
return y_positions
class RotatoryPositionEmbedding2D(nn.Module):
def __init__(self, seq_len, embed_dim):
super().__init__()
self.embed_dim = embed_dim // 2 # Split the dimensions into two parts. We will use 1 part for x-axis and the other part for y-axis
n_patches = seq_len - 1
x_positions = get_x_positions(n_patches, start_idx=1).reshape(-1, 1) # N -> N, 1
x_sin, x_cos = self.generate_rope1D(x_positions) # 1, 1, N, E//2 , 1, 1, N, E//2
self.register_buffer("x_cos", x_cos) # Register_buffer for easy switching of device
self.register_buffer("x_sin", x_sin) # Register_buffer for easy switching of device
y_positions = get_y_positions(n_patches, start_idx=1).reshape(-1, 1) # N -> N, 1
y_sin, y_cos = self.generate_rope1D(y_positions) # 1, 1, N, E//2 , 1, 1, N, E//2
self.register_buffer("y_cos", y_cos) # Register_buffer for easy switching of device
self.register_buffer("y_sin", y_sin) # Register_buffer for easy switching of device
def generate_rope1D(self, sequence):
'''
Create theta as per the equation in the RoPe paper: theta = 10000 ^ -2(i-1)/d for i belongs to [1, 2, ... d/2].
Note this d/2 is different from previous x/y axis split.
'''
sequence = F.pad(sequence, (0, 0, 1, 0)) # N, 1 -> N + 1, 1 = S Pad with 0 to account for classification token
thetas = -2 * torch.arange(start=1, end=self.embed_dim//2+1) / self.embed_dim # E//4
thetas = torch.repeat_interleave(thetas, 2, 0) # E//2
thetas = torch.pow(10000, thetas) # E//2
values = sequence * thetas # S, 1 * E//2 -> S, E//2
cos_values = torch.cos(values).unsqueeze(0).unsqueeze(0) # S, E//2 -> 1, 1, S, E//2 Precompute and store cos values
sin_values = torch.sin(values).unsqueeze(0).unsqueeze(0) # S, E//2 -> 1, 1, S, E//2 Precompute and store sin values
return sin_values, cos_values
def forward(self, x):
x_x = x[:, :, :, :self.embed_dim] # B, H, S, E//2 Split half of the embeddings of x for x-axis
x_y = x[:, :, :, self.embed_dim:] # B, H, S, E//2 Split half of the embeddings of x for y-axis
x_x1 = x_x * self.x_cos # B, H, S, E//2 * 1, 1, S, E//2 -> B, H, S, E//2 Multiply x-axis part of input with its cos factor as per the eq in RoPe
x_x_shifted = torch.stack((-x_x[:, :, :, 1::2], x_x[:, :, :, ::2]), -1) # B, H, S, E//2 -> B, H, S, E//4, 2 Shift values for sin multiplications are per the eq in RoPe
x_x_shifted = x_x_shifted.reshape(x_x.shape) # B, H, S, E//4, 2 -> B, H, S, E//2
x_x2 = x_x_shifted * self.x_sin # B, H, S, E//2 * 1, 1, S, E//2 -> B, S, E//2 Multiply x-axis part of x with its sin factor as per the eq in RoPe
x_x = x_x1 + x_x2 # Add sin and cosine value
x_y1 = x_y * self.y_cos # B, H, S, E//2 * 1, 1, S, E//2 -> B, H, S, E//2 Multiply y-axis part of input with its cos factor as per the eq in RoPe
x_y_shifted = torch.stack((-x_y[:, :, :, 1::2], x_y[:, :, :, ::2]), -1) # B, H, S, E//2 -> B, H, S, E//4, 2 Shift values for sin multiplications are per the eq in RoPe
x_y_shifted = x_y_shifted.reshape(x_y.shape) # B, H, S, E//4, 2 -> B, H, S, E//2
x_y2 = x_y_shifted * self.y_sin # B, H, S, E//2 * 1, 1, S, E//2 -> B, H, S, E//2 Multiply y-axis part of x with its sin factor as per the eq in RoPe
x_y = x_y1 + x_y2 # Add sin and cosine value
x = torch.cat((x_x, x_y), -1) # B, H, S, E//2 cat B, H, S, E//2 -> B, H, S, E Combine x and y rotational projections
return x
Multi Head Attention
We implement the version indicated on the ViT paper, using 12 heads.
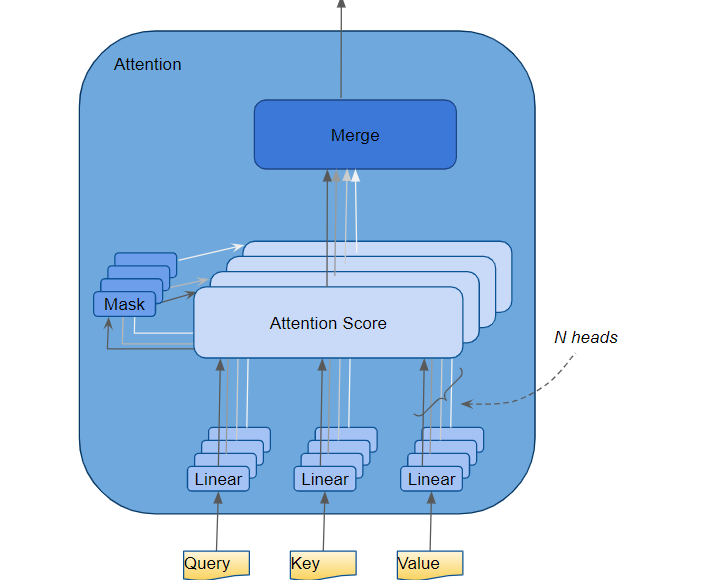
The way in which attention heads work is that each head is focused on a specific aspect of the token sequence, and to understand how the various tokens relate to eachother.
A shared linear layer projects X into Q, K, and V, which are then split across heads. Each head operates on its own 64-dim slice then the attention is calculated as Attention(Q, K, V) = softmax(QK.T / √head_dim) · V. Then the attentions calculated by each head get concatenated then to be projected linearly so that the attention calculated by each head gets “mixed”, which allows the cross-head reasoning to happen.
This mechanism is like when you’re working on a project with 12 team members all focusing on a different aspect of the project and submitting your findings on a report and then doing a team meeting at the end of the day to sum up your findings and evaluate the full picture.
class MultiHeadAttention(nn.Module):
def __init__(self, embed_dim, num_heads, seq_len):
super().__init__()
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.qkv = nn.Linear(embed_dim, 3 * embed_dim)
self.proj = nn.Linear(embed_dim, embed_dim)
self.rope = RotatoryPositionEmbedding2D(seq_len, self.head_dim)
def forward(self, x):
B, S, E = x.shape # [batch_size, 197, 768]
qkv = self.qkv(x) # [batch_size, 197, 2304]
qkv = qkv.reshape(B, S, 3, self.num_heads, self.head_dim) # reshapes to [batch_size, 197, 3, 12, 64]
q, k, v = qkv.unbind(2) # splits into [batch_size, 197, 12, 64]
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
q = self.rope(q)
k = self.rope(k)
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5) # dot prod between every key and query. resulting in [B, 12, 197, 197]
attn = attn.softmax(-1)
x = (attn @ v).transpose(1, 2).reshape(B, S, E)
return self.proj(x)
Transformer Encoder Block
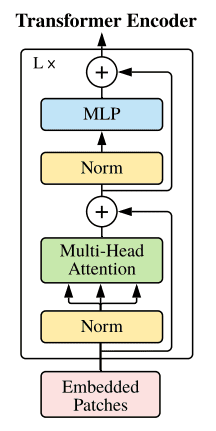
class TransformerEncoderBlock(nn.Module):
def __init__(self, embed_dim, num_heads, mlp_dim, seq_len):
super().__init__()
self.attn = MultiHeadAttention(embed_dim, num_heads, seq_len)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, mlp_dim),
nn.GELU(),
nn.Linear(mlp_dim, embed_dim)
)
self.norm1 = nn.LayerNorm(embed_dim)
self.norm2 = nn.LayerNorm(embed_dim)
def forward(self, x):
norm1 = self.norm1(x) # normalize
x = x + self.attn(norm1) # run attention + residual connection
norm2 = self.norm2(x) # normalize
x = x + self.mlp(norm2) # transform each patch + residual
return x
The ViT
The ViT we’re going to use in this example will have a depth of 6. Its sequence length is equal to our patch number + 1 for the CLS token. The CLS token is the token that is going to contain the features of our image that will be fed to our final MLP layer which is going to do the actual prediction. This token is going to be added as a prefix to our patch tokens, and through the self-attention layers, the CLS token will interact with all the patch tokens, collecting contextual information.
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, num_classes=10, embed_dim=768, num_heads=8, depth=6, mlp_dim=1024, channels = 1):
super().__init__()
seq_len = (img_size // patch_size) ** 2 + 1 # Our seq len is going to be the num of patches + one CLS token
self.patch_embedding = PatchEmbedding(img_size, patch_size, channels , embed_dim) # patch the image
self.transformer_blocks = nn.ModuleList([
TransformerEncoderBlock(embed_dim, num_heads, mlp_dim, seq_len) for _ in range(depth)
]) # Our ViT is going to have a depth of 6.
self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim)) # Assign the CLS token
self.mlp_head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
B = x.size(0) # batch size
x = self.patch_embedding(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # cls token is shaped [1, 1, 768] this expands it to [B, 1, 768]
x = torch.cat((cls_tokens, x), dim=1) # concatenate the cls token
for block in self.transformer_blocks:
x = block(x) # run the input through the 6 transformer blocks
return self.mlp_head(x[:, 0]) # spit out the answer
This particular example was specifically made to work on a chest x-ray multi-label classification task the full example with a sample dataset can be found on: link to notebook.
Enjoy Reading This Article?
Here are some more articles you might like to read next: